



1 前言
20世紀60年代 IBM 數據庫管理產品 IMS 技術的推出,為數據庫的發展奠定了基礎。隨后,各國先后開始建立材料數據庫,為材料標準、科研數據提供結構化的儲存途徑以及信息查詢等功能。
2011年美國提出發展材料基因工程,即數據庫、高通量計算方法與高通量實驗方法三大要素,為加速材料的智能設計作技術支撐。材料數據庫的作用和地位隨之變得更加突出: 一方面,材料數據庫可為高通量實驗以及高通量計算結果提供海量數據存儲空間;另一方面,材料數據庫為高通量計算提供參數,或通過挖掘數據庫中的知識模型,指導材料設計。
數據挖掘是數據庫發現知識模型的重要方法,是一個通過從不完全的、有噪聲的、模糊的、隨機的大型數據庫中,發現隱含的、未知的、可能有用的并且最終能被理解的模式的重要過程。雖然早在 20 世紀初期基于數據挖掘的數學基礎就已基本成熟,但直到計算機的出現和計算能力的提升,大數據分析、數據挖掘等操作才變得更加切實可行。將數據挖掘方法應用到材料數據庫的規律學習中,是指導新材料設計開發的一個重要手段。
本文針對國內外材料數據庫和數據庫技術的發展應用現狀進行了綜述,根據材料研發和理性設計新模式的發展需求,討論了構建材料基因工程所需的材料數據庫和數據挖掘技術目前存在的問題和未來發展方向。
2 材料數據庫
2.1 傳統材料數據庫
以歐美、日韓等為代表的發達和新興工業國家從20世紀七八十年代起,先后開始發展材料數據庫,目前都已擁有一定數量的材料數據庫,涵蓋了黑色金屬、有色金屬、高溫材料、復合材料、陶瓷材料、橡膠、核工業材料、功能材料等各種材料的成分、相圖、晶體結構、性能參數等數據。我國也從20世紀80年代開始由科研院所、企業自主建立了大量不同規模、分散獨立的材料數據庫,如鋼鐵研究總院的合金鋼數據庫、中國航發北京航空材料研究院的航空材料數據庫、北京有色金屬研究總院的有色金屬數據庫、清華大學的新材料數據庫、西北工業大學的復合材料數據庫、北京機電研究所的材料熱處理數據庫等上百個專業材料的數據庫。
根據存儲數據種類的不同,材料數據庫主要分為:材料熱力學和相圖數據庫、晶體結構數據庫(如無機晶體學數據庫(ICSD))、材料性能數據庫(標準或實驗)、工藝性能數據庫(如熱處理數據庫、金屬切削數據庫等)、特殊性能數據庫(如腐蝕數據庫和疲勞數據庫)、專用數據庫(如航空材料數據庫、汽車材料數據庫)等。根據存儲數據形式的不同,數據庫可分為數值型、文獻型和文獻/ 數值綜合型。根據存儲數據的服務模式,可分為離線型數據庫和在線型數據庫。由于早期建立的傳統材料數據庫主要是離線型,多服務于研究機構或組織的數據存儲和研究,存在規模小、用戶局限性高、商業化程度不高等缺點,因而其更新和應用受到人力、物力的限制,甚至部分數據庫逐漸銷聲匿跡。
隨著web網絡技術的普及和快速發展,國內外較活躍的材料科學數據庫開始以在線方式管理和服務,提高了材料數據庫的商業化程度,強化了對用戶的服務膜式。在線數據庫的主要優勢是更易推廣和數據共享,通過將數據庫商品化為外部機構提供有償服務,間接推動了數據庫的應用和全面快速發展。目前,國際知名的商業化材料在線數據庫有美國的MatWeb和ASM International、瑞士的Total Materria、日本的NIMS、德國的Key to Steel等,詳情如表1 所示。
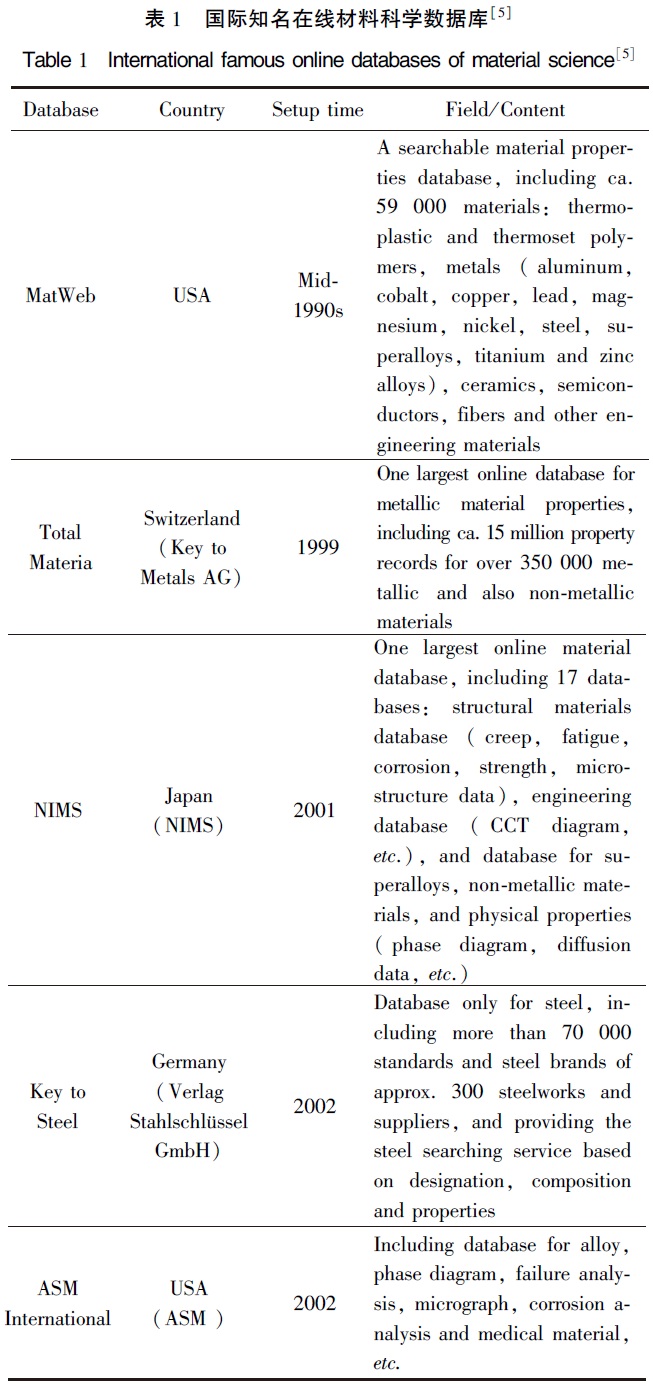
我國材料數據庫的商業化發展也隨著移動互聯網的興起得到極大提速。以鋼研·新材道、材易通、歐冶知鋼為代表的一批在線數據庫服務平臺先后出現。其中鋼研·新材道的“全球鋼材高端云服務”是依托于鋼鐵研究總院國內頂尖研發團隊和65年的技術積淀建立起來的材料數據和云服務平臺,其Atsteel在線材料數據庫包含上千個國內外標準、上萬個牌號的材料性能數據,以材料大數據和定制研發為核心理念,致力于技術市場化的“互聯網+” 之路,為中高端材料用戶提供研、產、檢、造、用的全產業鏈服務。成都材智科技有限公司建立的MatAI材料智能設計平臺具有能夠根據用戶需求提供數據管理和新材料設計優化等新功能。
傳統材料數據庫的主要功能是數據存儲和數據管理,同時還提供數據檢索服務,方便用戶快速獲取感興趣的數據信息。例如日本的NIMS數據庫就專門配套建立了MatNavi檢索系統,使用戶可以根據關鍵字/數值、樹形節點對數據庫的相關內容進行檢索。美國MatWeb數據庫也提供了基于數值、關鍵內容、類別的檢索方法。我國鋼研·新材道的Atsteel在線材料數據庫增強了數據庫的檢索功能,除了以關鍵字、材料牌號檢索的方式外,還提供成分、性能的區間范圍值及其他多參數組合的高級檢索功能,滿足用戶的各種檢索需求。
2.2 材料基因工程的共享數據庫
美國提出的材料基因工程理念,形成了材料數據庫的新發展方向。目前,歐美國家建立材料基因工程數據庫,除了發展新學科的獨立材料數據庫外,更希望搭建一個包含各種硬件、軟件和專用數據傳輸標準的數據共享平臺,如美國正在建設的Globus數據庫平臺。通過特殊的信息工程技術,保證大數據易存儲和搜尋等功能,既可將各地分散的傳統材料數據庫連入整個材料基因數據庫共享平臺,又可鼓勵科研人員上傳、發布新的科學成果,共享數據集;通過合理的材料數據庫傳輸標準設計,滿足各學科的數據存儲需求和應用;而且通過數據庫平臺的軟件集成進行在線計算,實現數據自動收集和數據挖掘,如Materral Project平臺。
促進材料基因工程數據庫建設和發展的關鍵是數據共享。美國在數據共享方面采取了很多措施,21世紀初期為了促進“人類基因組”項目數據庫的建立,鼓勵科學家快速分享DNA數據,提倡在24 h內上傳到公共GenBank數據庫中。隨著材料基因工程理念的提出,美國科學技術政策局(OSTP)和美國國際開發署(USAID)于2013年和2016年先后出臺了“公共訪問計劃”,要求,由OSTP和USAID等資助的科學研究數據需要在一定時間內公開,使公眾、企業和其他科學人員能夠獲取。美國國家科學基金委(NSF)也推出了“宣傳和共享研究結果”的政策,鼓勵科學人員能夠共享在NSF資助的工作過程中創建或收集的主要數據、樣本、實物和其他材料。我國的科學數據共享工程自2001年底啟動了氣象科學數據共享試點以來,已在24個部門開展了相應的科學數據共享工作。整體而言,目前國內外的數據共享工作,主要是先通過科研聯盟進行再不斷擴散,并建立數據貢獻積分制度顯示不同科研用戶的數據貢獻率,從而間接反映其在相關領域的成果和影響力。
為了保護共享數據的權利和所屬,目前國內外的共享數據庫平臺借鑒期刊論文模式,為每個上傳的科學數據(集)注冊唯一的DOI標識符,促進數據的保存、參考和引用。美國材料數據平臺(MDF)建立的可以發布數據以及查詢數據的共享數據庫平臺Globus,就是基于DOI對數據進行標識。通過該平臺,可以搜索MDF連接的各種數據庫/數據集里面保存的所有計算和實驗數據,包括NanoMine、PPPDB、Khazana Polymers、KhazanaVASP、JANAF、SLUCHI(VASP)、OQMD等十幾個數據庫。我國也積極推動共享數據庫、在線數據庫的發展,搭建了“材料科學數據共享網”平臺,集合了分布在全國各地的30余家科研單位的海量數據資源,包括黑色金屬、有色金屬、復合金屬、有機高分子、無機非金屬等各類材料科學數據,為國家基礎條件建設提供了雄厚的材料科學數據資源共享服務與應用支撐。該平臺目前也是通過提供標準的數據DOI注冊系統以及數據采集標準,保證上傳數據的標識性和結構化。近年來,隨著區塊鏈技術的不斷成熟和發展,已有一些將區塊鏈技術引入到材料數據庫中的設想,實現對數據來源的標記,進行數據的版權保護,激發大家共享數據的熱情。
高質量的共享材料數據對于材料基因工程具有重要的意義,不僅可以作為模擬計算的輸入參數,也可以作為知識發現的樣本數據,還可以為發現新的理論和技術提供線索。因此,數據的可信度是構建材料數據庫時需要關注的一個重要問題。目前的主要解決方法是:一方面通過領域專家或數據庫專員進行數據審核,并提供領域專家認證碼,保證數據的可信度;另一方面建立完整規范的統計數據質量控制體系,通過進行相似數據的對比,判斷數據的可信度或進行數據補充和修復。
2.3 材料基因工程數據庫的發展方向
除了數據共享、存儲和查詢外,材料基因工程的數據庫還需要加強對分散的、已建立的數據庫進行整合、利用,通過軟件集成實現數據自動收集功能,為大數據的學習和數據挖掘提供數據,指導新材料的研發。因此,材料基因工程的材料數據庫開始發展如數據庫匹配、數據自動收集、在線可視化、在線集成計算、在線分析等新功能。
2.3.1 數據庫的匹配功能
數據庫的自動匹配技術是將人工智能技術、模式識別等數據挖掘方法應用到材料數據庫中,建立數據庫之間的數據關聯性,是數據挖掘技術在材料數據庫中的一個成功應用。在數據庫“云”概念的基礎上,通過數據庫的自動匹配算法可以實現“云”中的分布式數據庫、異構,數據庫或多類型文件之間的連接,如圖1所示。
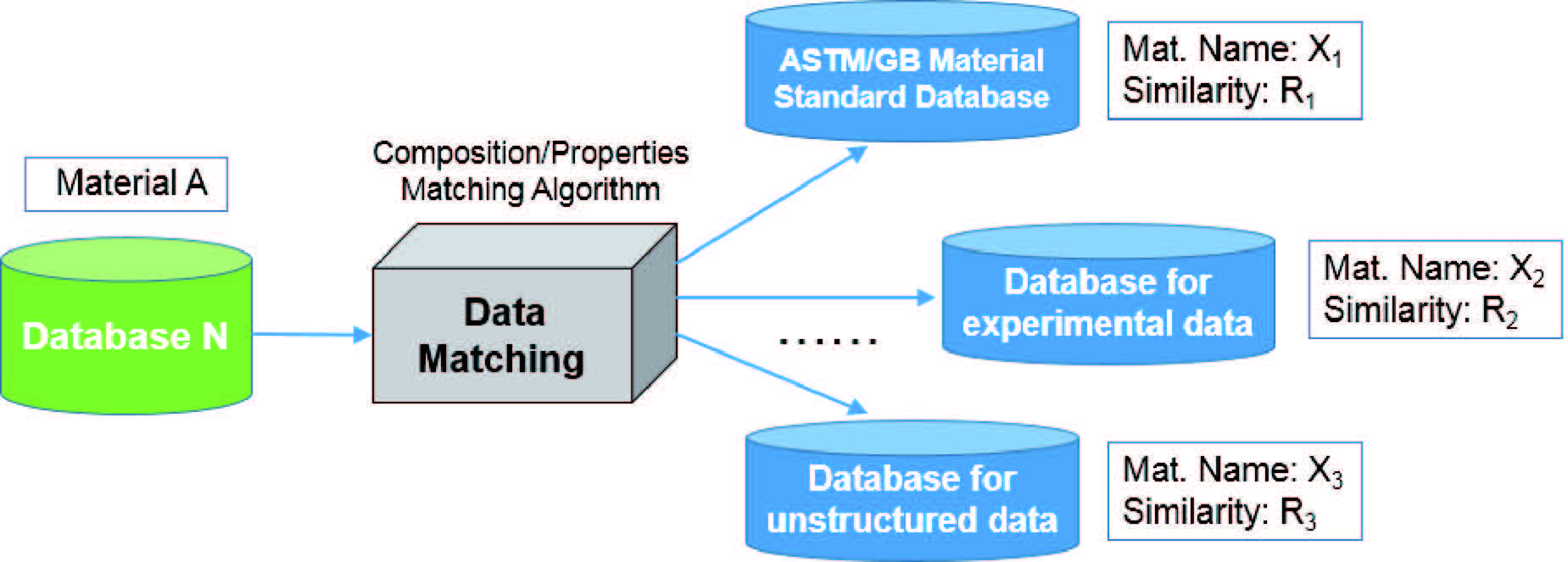
圖1 數據庫匹配技術流程圖
數據庫自動匹配功能的主要優勢是可以解決不同材料數據庫之間存在的數據結構差異性、各國材料標準牌號和命名方式的不一致性、數據上傳文件格式的多樣性以及單一數據庫中的信息不完整性等問題。在材料數據庫中使用數據自動匹配技術,可以實現“小數據”到整個數據庫系統的關聯,獲取相近材料的完整性能數據,是“小數據”換“大數據”的共享過程,也是實現分散數據庫之間關聯的一個重要方法。
德國的Key to Steel以及Matmatch等部分商業化在線數據庫具有一定的多國牌號對照匹配查詢以及數據庫中相似材料的查詢功能,但應用范圍比較窄,僅適用于國內外產品牌號數據信息的對比。而我國的Atsteel數據庫配套開發了多國鋼鐵材料牌號的自動匹配技術和功能,既可以實現各國相似材料牌號之間的關聯匹配,還可以實現標準數據庫、實驗數據庫、私有數據庫等不同數據庫之間的關聯查詢。目前該項數據匹配技術已經推廣到鋼鐵材料的焊材匹配應用中,可以為焊接母材與焊材的匹配提供合適的材料選擇方案。以460MPa強度級別的系列鋼材為例,基于北京鋼研新材科技有限公司的鋼鐵數據庫和焊接數據庫,利用數據匹配技術進行了母材和焊材的匹配設計,如表2所示。可見通過數據匹配技術為母材設計匹配的焊材,基本與《焊材手冊》推薦的相同強度級別的材料相吻合。其中,由于新的焊材數據庫包含了最新的焊材牌號,因而數據匹配算法給出的很多結果是一些新的焊材牌號。目前國外還沒有見到有任何關于母材-焊材匹配計算的相關報道,而且國外的焊材數據庫也較少,大多為焊接工藝數據庫。
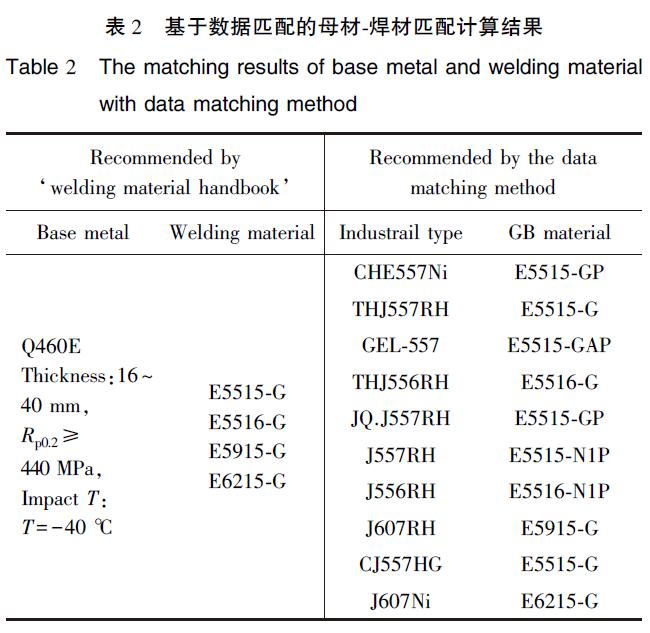
表2 基于數據匹配的母材-焊材匹配計算結果
瑞士Total Materia數據庫開發的SmartComp材料智能判斷功能相當于一種匹配檢索功能,主要是通過對來自光譜儀或其他分析來源獲得的金屬化學成分進行智能識別,獲得對應的材料金屬牌號,為材料的智能識別和數據庫自動分辨數據提供了新思路和方向。
2.3.2 數據庫的數據收集和輸出功能
數據的收集功能決定了數據庫的發展規模和活力。建立數據的自動收集和輸出功能,實現數據庫與高通量實驗、高通量計算的連接,是材料基因工程數據庫發展的另一個重要方向。
互聯網、云數據技術的發展在一定程度上為數據的收集、積累提供了支撐。共享數據庫通過提供數據自主上傳的接口,可實現用戶自服務的數據收集上傳功能。國家材料環境腐蝕平臺建立了“腐蝕大數據”和環境數據的大通量高密度采集、無線傳輸及入庫的功能,可實現數據庫數據的自動積累。目前國內外團隊開始研究新型軟件,可自動通過閱讀材料科學實驗論文獲取晶體結構等相關信息,為數據的自動收集提供了便利。但是如何通過論文信息的數字化識別全面獲取數據、數據來源及實驗條件,也是需要考慮的一個重要問題。
面對用戶對數據庫的輸出需求,目前一些在線數據庫可根據用戶權限有針對性地為用戶進行數據分析、建模計算從而提供相關數據及格式的輸出功能。MatWeb數據庫就為用戶提供以CSV、Excel等格式輸出數據庫中數據的服務,方便用戶線下對數據進行對比分析。此外,還提供輸出包含材料參數的通用計算軟件專用格式文件,可直接應用于Solidworks、ANSYS、COMSOL等軟件的結構材料計算建模中。
2.3.3 數據庫的在線集成計算和分析功能
材料基因工程數據庫的另一個重要發展方向是能夠在數據庫的基礎上實現在線分析、軟件集成計算以及數據結果自動存儲等功能。
通過在線集成第一性原理、熱動力學等成熟的材料計算軟件或程序進行計算,能夠為數據庫補充大量的材料結構、性能、相變等特征參量,而計算獲得的數據同樣能夠用于數據挖掘和指導新材料的開發。在材料基因工程計劃中,美國能源部(DOE)牽頭伯克利實驗室負責建立的Material Project就是一個數據庫集成平臺,其包含了600000多種材料和數據,提供了第一性原理的材料計算平臺,允許用戶對計算數據進行共享,目前已有超過20000名用戶利用該平臺進行新材料設計和優化。杜克大學創建的AFLOWlib數據庫,利用AFLOW材料高通量計算算法,通過在線集成VASP、ESPRESSO等軟件,實現了對已知材料電子分布、晶體結構、能量計算以及新型材料結構的自動預測,并可自動存儲計算結果到數據庫體系中,通過高通量計算不斷擴充數據庫的數據量。目前該數據庫已有106數量級的不同材料,其中,有超過108數量級的材料性能數據是通過計算獲得的。美國西北大學推出的開放量子材料數據庫(OQMD)、中國的MatCloud高通量材料集成設計平臺也具有相似的工作機制,通過調用VASP或CASTEP等第一性原理軟件在超級計算機上進行大批量計算,再將相應的計算結果保存到數據庫中,最終通過大數據分析來指導新材料設計。日本NIMS開發的COMPOThermo在線計算軟件,通過集成界面熱導率數據庫,可制定特殊熱性能要求的復合材料。目前材料數據庫集成第一性原理計算軟件主要在功能材料的設計領域獲得了較多成功的應用,同時在復雜的結構材料設計方面也有一定的應用。
此外,材料數據庫也開始考慮數據的在線可視化、在線分析等功能。成都材智科技有限公司建立的MatAI材料數據管理平臺可根據需求建立集成基礎的數據對比分析、數據統計和可視化工具的材料數據庫,以便在線進行散點圖的分析、曲線的對比和統計的可視化。目前,一些數據庫還可通過對熱力學計算軟件的集成連接,利用獲得的材料熱力學數據,配合數據庫中其他數據共同進行數據挖掘和分析。
3 數據挖掘方法在材料科學中的應用
3.1 數據挖掘方法簡介
數據挖掘基本流程為: 確定目標→數據庫取樣→數據預處理→數據挖掘建模→知識獲取和解析→應用,如圖2所示。將清洗預處理后的樣本數據分為3類:訓練型數據、驗證型數據和測試型數據,再用于模型學習、驗證和測試。
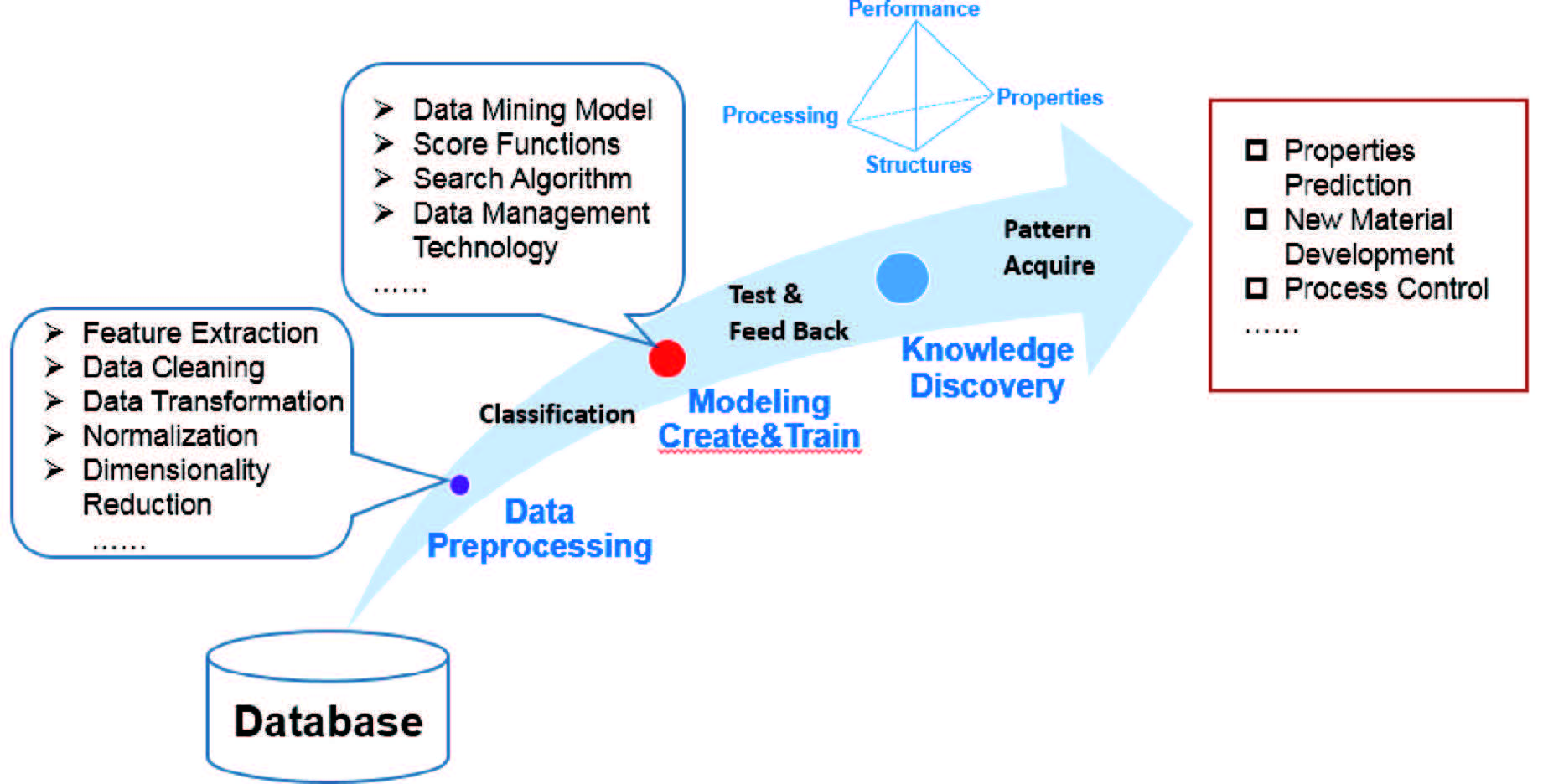
圖2 數據挖掘的基本流程
一個完整的數據挖掘算法通常是由模型結構、評分函數、搜索方法、數據管理技術幾個基本模塊組合構成。例如一個反向傳播神經網絡(BP-ANN)數據挖掘算法通常是由神經網絡模型結構、誤差平方函數、參數梯度下降尋優等模塊構成。組合不同的模型結構、評分函數、搜索方法等可以生成數量龐大的挖掘算法。此外,降維方法也被應用到數據處理中,如主成分分析(PCA)法就常被用于微觀組織形貌等的降維處理,使得微觀組織能夠作為輸入變量參與數據挖掘學習,從而通過回歸、神經網絡或其他模型方法最終建立工藝-微觀結構-性能關系。
數據挖掘的方法根據任務目的可分為預測性和描述性方法,根據學習方式可分為監督學習和無監督學習方法。在材料科學領域,目前常用的數據挖掘算法主要有:回歸、分類、聚類、智能優化,如圖3所示。其中,神經網絡和支持向量機是機器學習的兩大主要流派,既可用于回歸又可用于分類和優化。

圖3 材料科學中常用的數據挖掘算法
神經網絡最初起源于1957年Rosenblatt發明的單層感知機,隨著非線性問題需求的增加,多層神經網絡不斷發展。神經網絡基本原理是利用權重連接輸入層、隱藏層、輸出層之間的組合神經單元,并不斷訓練連接的權值直至計算結果足夠逼近預期值,從而解決復雜的計算問題。隨著多層神經網絡的發展應用,深度學習的概念被提出,卷積神經網絡、解積神經網絡等更復雜的神經網絡算法也隨之出現,如圖4所示。
圖4 不同類型的多層神經網絡
支持向量機(SVM)是由Cortes和Vapnik等于1995年首先提出的,屬于二分類模型算法,其基本原理是通過線或者超平面實現樣本集在二維或三維空間里面的間隔最大化。相較于其他分類統計算法對大樣本數據量的要求和難以解決復雜的高維度問題,SVM在解決小樣本、非線性及高維度的數據模式識別時也能獲得較好的結果,表現出了許多特有的優勢,并能夠被推廣應用到函數擬合等其他機器學習問題中。
3.2 數據挖掘方法在材料科學中的應用
隨著大數據的發展和計算機軟硬件實力的提高,90年代末期數據挖掘方法就已經開始被大量應用到材料科學研究及生產控制過程中,如材料性能預測和優化、新材料設計開發、生產過程的監控等方面。
3.2.1 材料性能預測和優化
數據挖掘在材料性能預測和優化方面的應用最為廣泛。其中多層神經網絡算法是使用較多的一種數據挖掘算法,常配合不同的優化算法進行解的快速搜索,如非線性最小二乘法、批梯度下降算法、沖量批梯度下降法、遺傳算法等。常規性能預測算法基本思路是:假定已知某材料的一組性能指標P與X個因子之間的相關性,利用數據庫中n個樣本的實驗數據集,設置各因子的可變范圍以及約束條件,通過數據挖掘的方法,建立P與X之間的線性或非線性關系,并據此指導材料的單一或多目標優化。目前,數據挖掘在材料的強度、沖擊韌性、淬透性、疲勞和蠕變等相關性能預測方面已有大量的應用。
基于熱軋鋼板的成分、熱軋工藝(溫度、變形、道次)等實際數據,Yang等通過3層前饋神經網絡模型,結合貝葉斯對權值進行優化訓練的方法,獲得了誤差較小的拉伸強度預測結果。Powar等通過11-5-7的3層神經網絡結構,建立了包含30CrMoNiV5-11的元素成分、奧氏體化溫度和時間、冷卻時間t8/5等的輸入層,與由屈服強度、抗拉強度、伸長率以及珠光體、貝氏體和殘余奧氏體的體積分數等構成的輸出層之間的關系模型,且相關性系數R大于90%。針對相變誘導塑性(TRIP)鋼,Bhat-tacharyya等利用11-15-1的3層神經網絡模型,采用雙曲正切函數作為傳遞函數,獲得了包含C,Si,Mn,P,Al,Nb,Cr的質量分數、臨界區退火溫度和時間、貝氏體等溫轉變溫度和時間的11個輸入層節點到殘余奧氏體含量的預測模型。Liu等利用前饋神經網絡模型對Nb-Si基高溫合金的微觀組織與性能之間的關聯關系進行了挖掘學習,建立了基于Nb5Si3的體積分數、形貌、尺度等微觀組織變量對抗拉強度、斷裂韌性等實現預測的模型。
遺傳算法-神經網絡(GA-ANN)結合算法被應用到了某FeCrNiMn奧氏體不銹鋼體積模量的預測中,且該預測結果與基于密度泛函理論(DFT)的第一性原理的計算結果非常接近,證明了GA-ANN算法預測的精準性。此外,在已獲得的第一性原理計算結果數據基礎上利用隨機森林等方法構建數據挖掘模型,獲取知識模型和重要的影響因素后,即可代替第一性原理計算直接預測Ni基、Co基高溫合金摻雜元素的置換能和幾何結構,間接節約了材料性能計算和設計的時間。可見,數據挖掘為第一性原理計算的加速提供了另一種思路和方向。
3.2.2 材料特征曲線擬合
數據挖掘算法在材料特征曲線的擬合方面也有著廣泛的應用。Haque等利用神經網絡,對獲得的大量實驗數據進行擬合,建立了不同馬氏體含量的系列雙相鋼的腐蝕疲勞裂紋擴展速率da/dN與應力強度因子變化量ΔK的關系模型,實現了其在雙相鋼腐蝕疲勞裂紋擴展速率預測中的應用。
在熱塑性變形方面,通過對材料流變應力應變實驗數據的學習,針對不同材料成分,可擬合和預測應變速率和溫度條件下對應的高溫熱壓縮時的流變應力應變曲線和本構方程,以及動態再結晶的體積分數和晶粒尺寸,從而為后期鍛造過程的多場耦合建模、應力應變計算和組織預測模擬提供精準的材料本構方程。然而,利用數據挖掘的模型分析成分對流變應力的影響還有待進一步深入的研究。
在焊接方面,數據挖掘算法除了被應用到材料焊接后的性能預測(如熱影響區的硬度),還被應用到了焊接熱源形狀參數的擬合預測中。例如通過對實際鎢極惰性氣體保護焊接(GTAW)過程中獲得的不同焊接條件(如電流、焊接速度)下雙橢圓體熱源尺寸數據集進行數據挖掘,可較好地擬合出焊接熱源形狀參數變化情況,并預測未知焊接條件下的形狀結果。通過擬合預測熱源模型,能夠為焊接過程的有限元模擬提供精準的熱源輸入模型,保證了更準確的溫度場計算結果。
3.2.3 質量預測及生產監控
基于風險最低原則,常采用支持向量機、決策樹、神經網絡等分類算法對材料生產過程參數進行在線異常監控以及質量預測。
在鋼生產過程中的表面質量分類和缺陷在線預測控制方面,數據挖掘算法已經獲得了較多的實際應用,基本上能保證預測和監控精準度在90%以上。其基本監控流程是: 通過在線缺陷圖像信息采集,獲取缺陷圖片的幾何特征(如長度、正方度、面積等)、圖片的灰度數據、織構特征信息(能量、粗糙度、對比度、方向等)等表征參數,再利用數據挖掘中的分類算法和優化算法組
合建模,快速實現缺陷的鑒定、識別和分類。
分類算法還被廣泛應用到焊接質量預測控制等相關方面。通過決策樹分類模型,根據焊接過程中的電流和電壓信號可以實現對焊接效果(有氣孔、完好、過燒)的評價,對焊接效果等級進行分類和在線監控;結合聚類和神經網絡的數據挖掘算法,可基于數據庫中焊接缺陷分類結果,判斷影響焊接穩定性的因素;利用支持向量機可對焊接的高熱輸入風險進行在線評估和預測。
此外,對材料服役過程的缺陷診斷,也能夠使用分類算法。決策樹和支持向量機等就被應用到對滾動軸承缺陷的分類和診斷工作中,通過前期數據的學習和模型建立,使得根據軸承的震動信號就可自動實現對缺陷狀況的診斷。
3.2.4 微觀組織的識別和分類
與指紋識別功能類似,數據挖掘方法也開始被應用到對材料微觀組織照片的識別和分類中,使得組織信息能夠數字化,為高通量實驗或數據庫的非結構化文件的分類和關聯提供了新的思路和方向。
Decost等利用支持向量機算法實現了對黃銅、球墨鑄鐵、灰口鑄鐵、亞共析鋼、高溫合金、退火孿晶等不同系列微觀組織照片的識別和分類,以便對存放有大量材料組織照片的數據庫進行分類管理。此外,Gola等利用支持向量機算法也實現了對金相組織照片和透電鏡照片中出現的馬氏體、貝氏體和珠光體的基體組織進行分類。
此外,數據挖掘方法以及PCA等降維方法也開始被應用到了三維場離子顯微鏡分析中,以獲得更精準的數據結果。PCA主要是通過對數據進行特征值分析,確定出需要保留的主成分個數,舍棄其他數據冗余和噪聲,從而實現數據的降維。PCA是目前圖像處理較為常用的降維方法。
3.3 數據挖掘在材料基因中的應用發展和問題
數據挖掘過程不需要考慮參數之間復雜的物理和化學意義,就可以直接從材料數據庫中挖掘出有價值的知識或模式,它能夠充分發揮材料數據庫甚至小數據量在材料設計中的作用。在材料基因工程項目的推動下,數據挖掘在材料設計中的應用不斷被深入和拓展。
根據材料基因工程理念,數據挖掘算法未來可以被集成、應用到材料數據庫以及高通量計算平臺中,通過對材料成分-工藝-組織-性能數據規律和知識的自動學習,進行多參數、多目標的優化計算,能夠大大提高材料設計速度,降低設計成本,更好地指導材料性能預測或新材料設計。目前,基于材料數據庫和高通量計算結果,數據挖掘技術已經開始成功運用到了功能材料等新材料的設計和開發中。徐一斌團隊在數據庫基礎上,通過支持向量機、回歸等機器學習方法獲得了高界面熱阻的材料組合,并結合高通量薄膜制備技術,制備出了目前世界上隔熱性能最高的無機納米復合薄膜。
數據挖掘算法的復雜性以及材料數據庫中相關參數的多樣性,決定了數據分析是一個需要多學科知識交匯和大量經驗積累的過程。Agrawal等基于NIMS數據庫中的鋼鐵材料疲勞數據庫,建立了針對材料疲勞強度設計的知識模型,對比了十幾種數據挖掘組合算法的精準性,包括線性回歸、決策樹、支持向量機、人工神經網絡、模型樹等,并獲得了包括材料成分、工藝參數、缺陷分布等25個輸入參數對疲勞強度的正負相關性影響,如圖5所示。因此,如何在已有材料數據庫中確定自變量和因變量,并選擇合適的數據挖掘算法,如何從獲得的結果中讀取知識,以及如何判斷數據挖掘獲得知識的準確性,是數據挖掘過程中需要深入研究的問題。
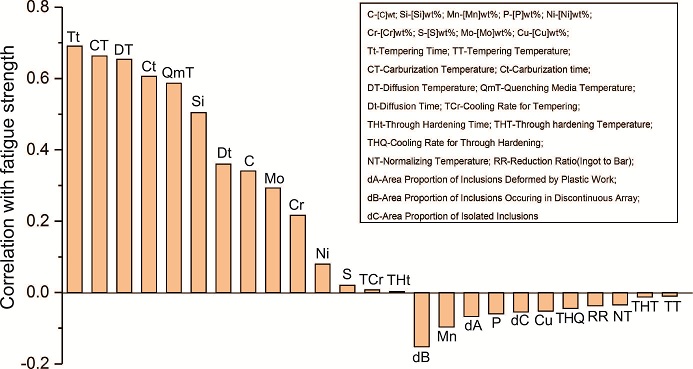
圖5 25 個不同參數與疲勞強度相關性的關系
確保數據挖掘結果準確性的一個重要因素是材料數據庫的數據可靠性。因此,在建立材料數據庫的過程中通常要求設置數據審查機制,以保證數據庫中所有上傳數據的正確性。當然在數據挖掘過程中,通過數據預處理可以對噪聲點、異常值進行清洗,一定程度上能夠減小數據誤差造成的分析結果偏差。然而,除了利用成功的實驗數據進行數據挖掘和分析外,失敗或不成功的實驗數據用于預測新材料的合成也獲得了較高的準確性,大幅提高了新材料研發的可能性。
4 結語
在材料基因工程中,數據挖掘需要與材料數據庫以及高通量計算相互結合、協同發展,才能更好地發揮其對材料加速設計的作用和意義。
(1)數據庫作為數據管理和存儲技術,為數據挖掘和高通量計算提供了輸入參數。材料數據庫目前已逐步從孤立的離線數據庫向在線數據庫和共享數據庫方向發展,但其結構化、標準化等方面還有待改善。逐步發展起來的數據庫云理念結合數據匹配算法方便了分布式數據庫之間的連接,為數據庫結構差異性問題提供了解決途徑。同時,需要進一步擴大數據量以實現材料數據庫的規模化進而提高數據挖掘結果的精準性。
(2)數據挖掘可為材料數據庫提供數據分析技術和方法,從已有的數據中發現知識和規律,加速材料設計。通過完善材料數據庫中的材料成分、工藝、組織、性能數據,再利用數據挖掘技術可建立成分-工藝-組織-性能之間的關系模型。掌握從海量的數據中選擇合適的樣本數據、建立參數的相關性,并精準地提取規律和解釋知識,是數據挖掘技術在材料設計中深入應用需要重點關心的方面。
(3)數據庫與數據挖掘技術的結合、數據庫匹配、數據自動收集、在線可視化、在線計算、在線分析等數據庫新功能的拓展,將使材料基因工程數據庫發展成為一個綜合性平臺,既是數據庫平臺,也是計算平臺和數據分析平臺。目前數據挖掘技術在數據庫中的應用大多都是線下操作,而且數據樣本的大小和數據的精準性也影響著數據挖掘的結果。未來,通過在材料基因數據庫中直接集成嵌入數據挖掘算法,進行數據在線自動學習、異常數據清洗、知識提取,以便更好地支撐材料設計,提高研發效率。
免責聲明:本網站所轉載的文字、圖片與視頻資料版權歸原創作者所有,如果涉及侵權,請第一時間聯系本網刪除。

官方微信
《中國腐蝕與防護網電子期刊》征訂啟事
- 投稿聯系:編輯部
- 電話:010-62313558-806
- 郵箱:fsfhzy666@163.com
- 中國腐蝕與防護網官方QQ群:140808414

“海洋金屬”——鈦合金在艦船的

腐蝕與“海上絲綢之路”