




第一作者:王萍。通訊作者:袁睿豪
通訊單位:西北工業大學凝固國家重點實驗室
文章鏈接:
https://www.sciencedirect.com/science/article/pii/S1359645425005622
描述符是基于機器學習的材料設計取得成功的關鍵先決條件。然而,如何為各種性能自動構建可泛化的描述符,并將其與設計標準相結合,仍然是一個長期存在的挑戰。本文通過設計一個整合了大型語言模型、領域理論約束([Mo]eq和d-電子理論)以及多目標全局優化的框架來克服這一難題。該框架融合了結構化(表格化的成分/加工數據)和非結構化(文本)數據,以獲得信息更豐富的描述符,從而促進材料設計。我們以鈦合金為案例,首先自動獲得了可很好地泛化于各種性能的描述符,從而實現了預測模型的優化。在此基礎上,我們提出了一種設計流程,從龐大的化學和加工空間中識別出幾種具有高潛力的、可增強競爭性能的合金,并通過實驗合成驗證了其可靠性。研究表明,從約50,000篇沒有明確物理學的文本中學習到的豐富描述符,能夠捕捉到與相穩定性、特定性能的合金化規則等相關的專業知識。我們提出的方法可應用于描述符尚不完善且結構化數據有限的其他材料設計領域。
背景介紹:
傳統描述符局限性:傳統描述符如元素含量、時效溫度所傳達的信息往往不足,導致機器學習模型和后續材料設計的效果不佳。這種問題在材料科學中尤為突出,尤其是可用于建模的數據有限。
現有豐富描述符信息量方法:基于物理的描述符,雖然可以通過引入基于物理的量(如相變相關屬性、熱力學指標)來豐富描述符信息量,但它們通常是特定于性質的,并且其選擇高度依賴于領域專業知識。基于坐標的編碼,這類方法(如編碼原子環境的矩陣)需要精心定義的編碼規則,且僅適用于符合這些規則的材料。現有方法都難以自動獲得適用于各種性質的、可泛化的描述符,并將其與材料設計標準結合起來。
主要圖片預覽:
大量的非結構化文本數據(如科學論文)蘊含著豐富的隱性知識,卻難以被現有機器學習算法直接利用。盡管近期語言模型在處理材料文本方面取得了進展,但它們仍未實現自動構建出能泛化到未知材料和多樣性質的通用描述符,這限制了在大規模材料空間中進行有效搜索的能力。為突破這一瓶頸,我們提出了一種創新性框架(圖1),其核心在于有效融合非結構化文本數據與結構化數據。以鈦合金設計為例,我們利用該框架從海量文本中自動學習并重構了合金成分,生成了通用性強的描述符。這些描述符不僅顯著提升了不同性質和算法的預測模型性能,更重要的是,結合領域理論和高效優化,我們成功從廣闊的化學與加工空間中篩選出了多個有望打破傳統強度-延展性或強度-模量權衡的合金。

圖 1. 本研究的工作流程如下:I. 多模態數據的收集與處理;II. 上游語言模型的訓練;III. 合金成分的豐富描述符生成及下游回歸模型的訓練;IV. 將回歸模型與領域理論和多目標優化相結合,設計具有競爭性能的亞穩態鈦合金;V. 可解釋性分析。

圖 2. 大型語言模型的訓練和部署。(a) 訓練樣本的格式(灰色標記表示被掩碼的樣本)以及通過 NSP 和 MLM 損失優化參數的語言模型的預訓練過程。(b) Transformer-Encoder 模型的具體架構。(c) 部署 Transformer 以豐富鈦合金成分的表示。(d) 注意力機制示意圖。
圖2a展示了LLM的訓練流程,包括使用超過46,000篇摘要構建正負樣本進行訓練,并利用MLM和NSP損失函數進行優化。圖2b進一步解析了LLM的輸入構成以及模型架構。圖2c展示了模型在推理階段為合金成分生成嵌入向量。圖2d則深入描繪了Transformer架構的核心,即自注意力機制,它能高效處理長序列并捕捉tokens之間復雜的語義和結構關系。鑒于LLM最初生成的768維描述符維度過高,制定了一系列降維策略。先使用皮爾遜相關性分析,接著運用遺傳算法(GA)進一步將維度優化至與傳統描述符相同的13維。以拉伸強度為例,圖3展示了GA如何通過迭代優化,使得最優描述符組合的R2值迅速收斂并穩定,從而確定了適用于不同性能預測的最佳13維豐富描述符集合。

圖3. 以拉伸強度為例,通過遺傳算法優化選擇六個下游回歸模型的豐富描述符。(a)LR,(b)GPR,(c)MLP,(d)SVR,(e)GBR,(f)RF。
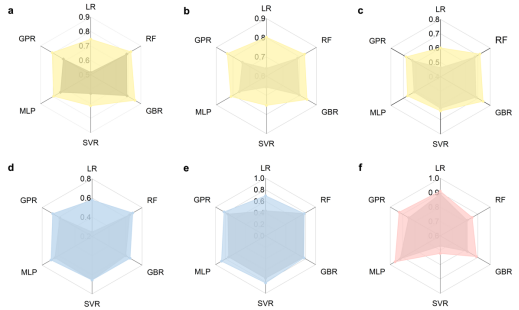
圖 4. 基于常規描述符(深色)和豐富描述符的回歸模型性能比較。每個模型的指標均來自測試集,采用五重交叉驗證。(a)、(b) 和 (c) 分別表示數據 S2 中的拉伸強度、屈服強度和伸長率。(d)–(e) 分別表示數據 S3 中的屈服強度和彈性模量。(f) 分別表示數據 S4 中的蠕變斷裂壽命。
圖4展示了本研究中豐富描述符在預測多種材料性能方面的卓越表現,并將其與傳統描述符進行了對比。這些結果清晰地表明,通過Transformer模型自動構建的豐富描述符對于不同的回歸算法和多種材料性能都具有良好的泛化能力。
圖5詳細闡述了本研究如何通過融合領域理論與機器學習來加速亞穩態鈦合金設計。首先利用鉬當量和d電子理論對百萬級候選合金進行預篩選,隨后結合豐富描述符、加工參數輸入機器學習模型進行性能預測和多目標優化(如平衡強度-延展性),最終通過對實際合成合金的驗證,成功篩選出并證實了具有突破性競爭性能的新型合金。

圖5. 鈦合金設計與實驗驗證。(a) 亞穩態合金設計流程。(b) 根據d電子理論圖篩選亞穩態合金(黃色區域),以不同的相和變形機制(從右到左依次為滑移、TWIP、TRIP)為特征。(c) 針對具有更高屈服強度和伸長率的候選合金進行多目標優化;(d) 屈服強度和彈性模量。 (e) 驗證建議的可靠性(A:Ti–5.2Mo–5.2Cr–4.0Al–4.4V–2.4Nb,B:Ti–5Al–5Mo–5V–3Cr–0.6Fe,C 和 D:不同加工的 Ti–6Mo–5V–3Al–2Fe,E:Ti–15.1V–3.1Al–2.5Cr–2.9Sn,F:Ti–11V,G:Ti–5Al–5Mo–5V–3Cr–1Zr,H:Ti–7.18Mo–2.99Nb–2.94Cr–3Al,I:Ti–1Al–8.5Mo–2.8Cr–2.7Zr)。
圖6深入剖析了本研究中豐富描述符的卓越性能來源,主要揭示了其編碼的物理知識和捕獲專家經驗的能力。在編碼物理知識方面,圖6a展示了描述符如何自發地從大量文本中學習并區分不同元素對合金相穩定性的影響,將元素精準分類;同時,圖6b和圖6c通過高皮爾遜相關系數證明,這些描述符甚至能在未明確輸入物理信息的情況下,隱含地捕捉到如價電子濃度和原子半徑等核心物理屬性,印證了大型語言模型學習文本中潛在物理規律的強大能力。在捕獲專家經驗方面,圖6d至圖6i通過可視化Transformer模型的注意力矩陣,揭示了描述符如何像人類專家一樣,識別出對特定材料性能(如高延展性、高強度或低模量)至關重要的合金元素,這與現有材料科學研究的結論高度吻合。

圖 6. 豐富描述符的可解釋性分析。(a)基于大型語言模型生成的嵌入對各種相穩定性元素進行聚類。(b)VEC 與嵌入第 62 維之間的 Pearson 相關性;(c)原子半徑與嵌入第 717 維之間的 Pearson 相關性。第 12 個區塊中,每種合金成分的兩個典型注意力頭對應的注意力矩陣如下:(d)和(e)代表 Ti-11Sn-26.2Nb,(f)和(g)代表 Ti-5Al-6.5Mo-1.5Fe,(h)和(i)代表 Ti-30Nb-1Mo-4Sn。顏色越深,表示兩個標記之間的注意力水平越高。
免責聲明:本網站所轉載的文字、圖片與視頻資料版權歸原創作者所有,如果涉及侵權,請第一時間聯系本網刪除。

官方微信
《腐蝕與防護網電子期刊》征訂啟事
- 投稿聯系:編輯部
- 電話:010-62316606
- 郵箱:fsfhzy666@163.com
- 腐蝕與防護網官方QQ群:140808414

“海洋金屬”——鈦合金在艦船的

腐蝕與“海上絲綢之路”